
June 16, 2025
Applying Digital Transformation Trends in Your Business: An Expert Guide for 2025
Learn about the latest digital transformation trends in healthcare, retail, manufacturing, and other industries from experts at Coherent Solutions.
Read more
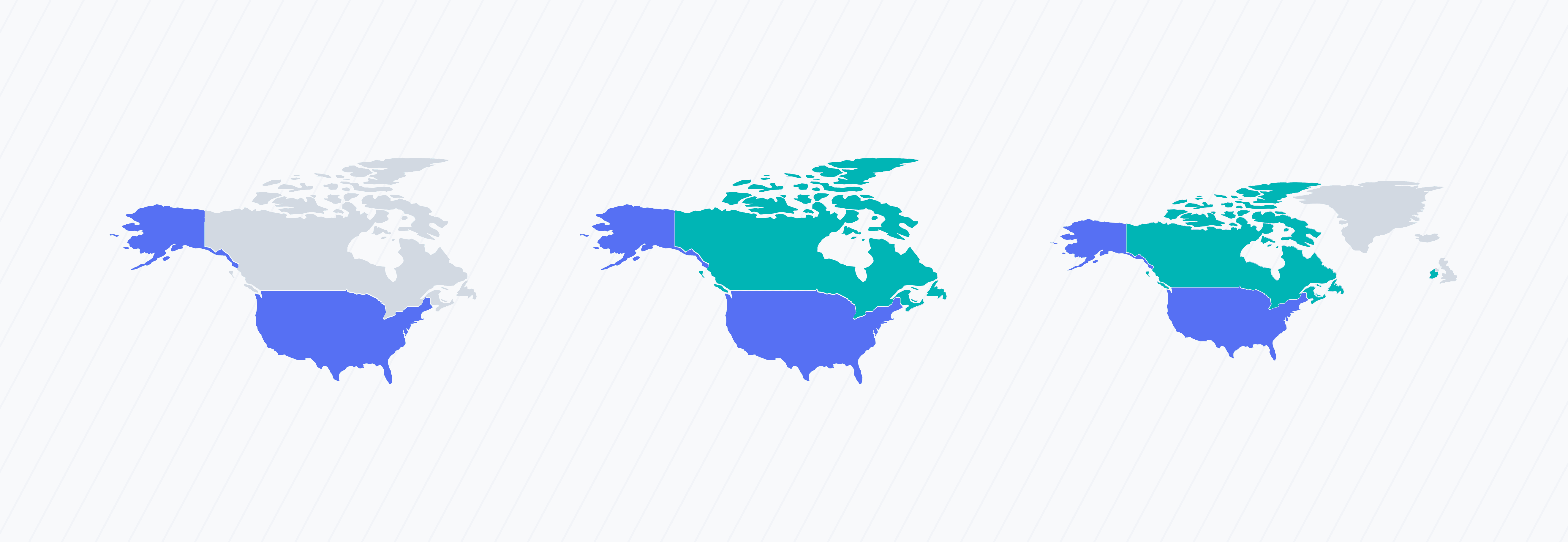
June 2, 2025
Should You Choose Offshore Software Development in 2025? Cost Efficiency and Other Pros & Cons
In this comprehensive guide, we delve into the nuances of offshore outsourcing—highlighting its benefits, challenges, and best practices.
Read more

May 26, 2025
Coherent Solutions Named a Top B2B Company for AI, NLP, and Robotics Services by Clutch
Coherent Solutions stands out as a top B2B provider for AI, NLP, and Robotics services, as recognized by Clutch. Learn more about our expertise.
Read more

April 25, 2025
AI Adoption Across Industries: Trends You Don’t Want to Miss in 2025
Learn about key AI adoption trends and how we help businesses across industries use AI for growth and efficiency, step by step.
Read more

April 17, 2025
From DevOps to Platform Engineering: What You Need to Know Before You Switch
Explore the key differences between DevOps and platform engineering—and how shifting to IDPs helps teams scale efficiently and innovate faster.
Read more

March 31, 2025
AI Without Overhead: Simplify AI App Development with ML.NET
Discover how ML.NET empowers .NET developers to create scalable AI applications. Simplify your AI adoption today with ML.NET models in place.
Read more

March 24, 2025
Coherent Solutions Expert Wins 2024 DevOps Dozen Award
Congratulations to Alexander Simonov of Coherent Solutions for winning the 2024 DevOps Dozen Award! His article highlights how DevOps professionals can thrive alongside AI.
Read more

March 18, 2025
Coherent Solutions Recognized as a Leading IT Services Provider in Minneapolis
Coherent Solutions is recognized by The Manifest for its excellence in IT consulting and software development. Read our latest client reviews.
Read more

March 15, 2025
6 Steps to Achieve Stable and High-Quality Releases with QA Automation Assessment
Discover how QA automation ensures stable and high-quality releases. Learn best practices to speed up code change response and reduce technical debt.
Read more

March 7, 2025
How Engagement Models in Software Development Set the Stage for Project Success
Unpack the gist of engagement models in software development and their pros and cons. See what makes sense for projects with various goals, budgets, and needs.
Read more